共计 1615 个字符,预计需要花费 5 分钟才能阅读完成。

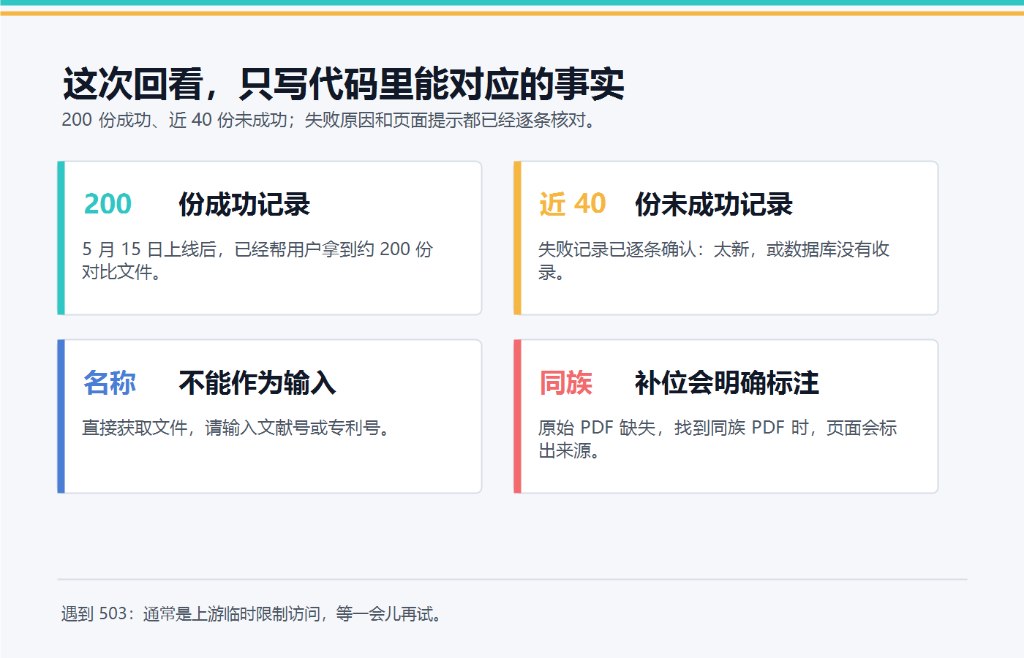
从 5 月 15 日上线到现在,这个对比文件下载程序已经帮用户拿到大约 200 份对比文件。
同时,也留下了将近 40 份没有拿到的记录。
做专利代理工作久了,我对这种小工具的要求其实不复杂。它不需要讲很多漂亮话,能把审查意见里的对比文件尽快拿到手,已经能省掉不少无效时间。真正要下判断、写意见、和发明人沟通,还在后面。可如果第一步就卡在找文件上,人的状态会被磨掉。
所以看到 200 这个数,我是开心的。有人真的用上了,它没有只停在我自己的电脑里。
但那将近 40 份失败记录也放在那里。我把这些记录一个一个确认过。看完以后,程序哪里该补,哪里不能乱写能力,反而清楚了很多。
先把话说清楚
这套程序做的不是专利检索。
这句话得先讲明白。直接获取文件,前提是你已经有文献号或者专利号。程序根据这个编号去精确获取对应文件,而不是根据专利中文名称去做检索。
如果只输入一个专利名称,那就不是“获取文件”了,而是“专利检索”。检索要处理的是另一个问题:怎么从名称、申请人、关键词、公开时间、技术主题里判断到底是哪一篇。这个程序现在做不到,也不打算把这个功能硬塞进去。
这不是限制谁使用,而是把事情分清楚。要直接拿文件,请输入文献号或专利号,比如申请号、公开号、授权公告号这类编号。
中文专利号和文献号这块,我也重新补了一遍。现在常见的 CN、ZL 写法,带不带小数点,带不带校验位,老格式还是新格式,基本都能识别。这个地方看起来不大,实际很费时间,因为真实用户给你的号码,往往不会只长一种样子。
更推荐的用法
单篇直接获取文件,适合临时补一篇材料。可这个网页 APP 最初想解决的,还是答复审查意见时的材料整理问题。
更省事的用法,是直接上传审查意见通知书。程序会根据通知书里的内容,定位审查意见针对的专利公开文件,也会把通知书里提到或引用的对比文件识别出来,再尽量准备可下载的 PDF。对正在答复审查意见的代理人来说,这才是它原本的工作方式。
页面里已经有打包下载的功能,压缩包里的文件名也会尽量带上“本案”“对比文件”和对应文献号。后面我还想把这块继续做得更顺手一点,让文件名和通知书里的引用项对应得更清楚。这样下载回来以后,不用再一份一份改名。
有这类需求的代理人、发明人,可以直接试用这套网页 APP。它不替代审查意见分析,但能把找文件、对文件、存文件这些前置工作少做一些。
找不到 PDF,原因其实就两类
我把失败记录一条条看过,最后落到的原因并不复杂。
一种是专利太新。有一部分公开日就是 5 月 15 日,离上线太近,外部数据库来不及收录,这种最常见。
另一种是数据库没有收录。
数据库没有收录,又会分出两种情况。一种是完全没有收录,PDF 没有,同族专利也没有。另一种是没有收录准确的文件,但是能看到同族专利。
后一种情况,我已经改了。现在程序发现原始 PDF 缺失时,会继续顺着同族专利去找有没有可用的 PDF 文件。如果找到了,会返回给用户,同时页面上会明确标注这是同族专利。这样至少不会让人把“拿到的是同族文件”误看成原始文件。
完全没有收录的情况,目前就没法自动变出来。程序能把失败说清楚,比假装成功更重要。
503 这件事
后台接口有时候会回 503。这个时候,最实在的做法就是等等再试。它不一定说明文件有问题,更多时候只是上游临时限制了访问。
我把这个提示也写进去了。用户不需要对着一个含糊的报错猜半天,知道“过一会儿再试”通常就够了。
我后来做了哪些改动
说到底,这次不是把功能说得更大,而是把它真正能做的部分理清楚。
能精确拿文件的,就继续做下去:输入文献号或专利号,程序去找对应文件。
原始 PDF 缺了的,先判断是不是太新,再看数据库里到底有没有收录。
如果同族专利里能找到可用 PDF,就返回,并且在页面上标出来源。
碰到 503,就提醒用户稍后再试。
这些调整做完以后,程序的样子没变得多花哨,但更贴近日常使用里的真实问题。
能帮到这么多人,我是真的开心。更准确地说,是开心里带着一点踏实。工具被用起来,才会知道它真正该往哪儿改。